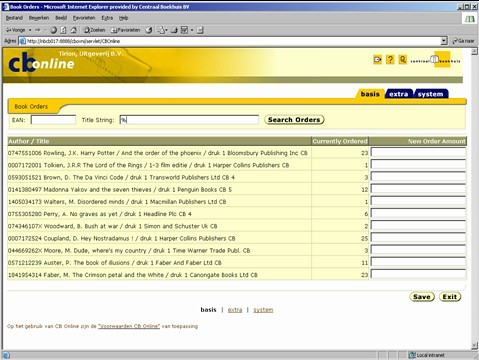
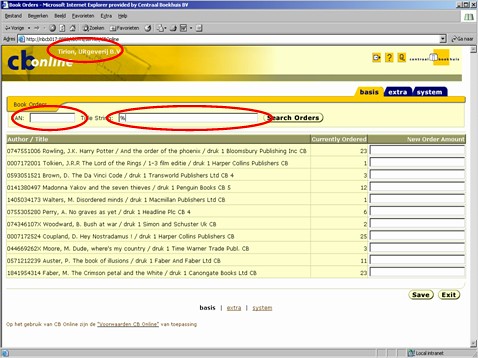
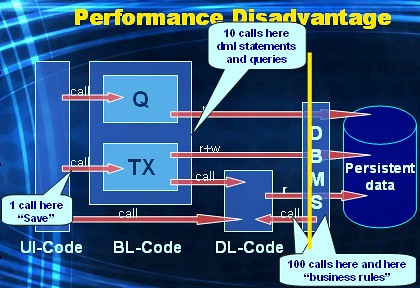
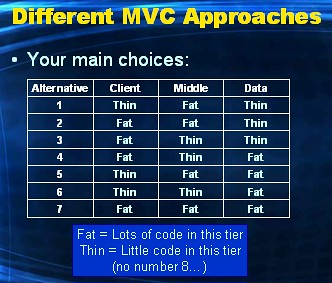
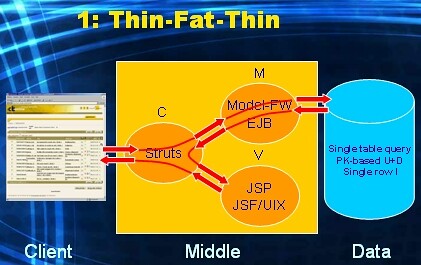
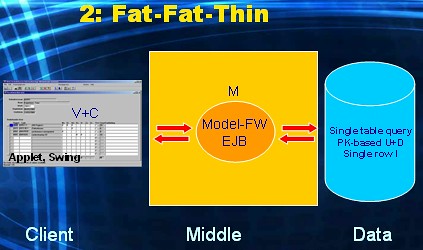
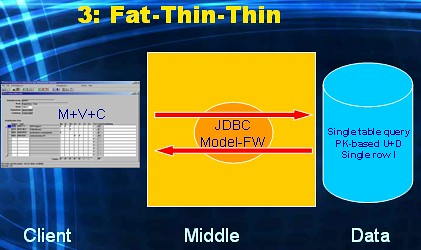
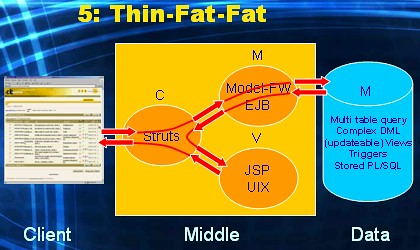
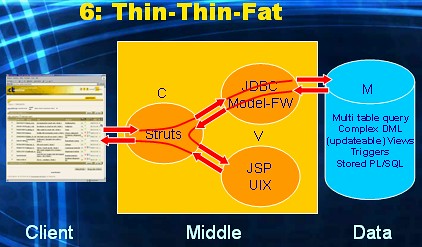
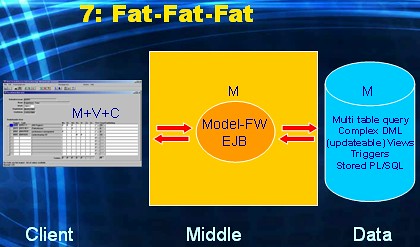
Sometimes the technology used for the UI-layer might be more comfortable using a SQL-based contract with the DBMS. So instead of calling a stored procedure, we would like to submit SQL-statement. More specifically, in the example at hand, a query.
Using SQL based contract
In this post I'll demonstrate how the same page can be serviced by the DBMS via a pipelined table function. Pipelined table functions are a great enabler of pushing business logic into the DBMS tier while at the same time enabling a SQL-based contract of the UI-layer with the DBMS.
Here's how we are going to setup the contract.

We'll use the application context feature inside the DBMS to first convey to the data-tier some context of the page. This will be exactly the same context as with the procedural contract: the username that's logged in, the EAN and the book (search) string. Then we'll develop a view that employs a pipelined table function that uses this context to produce the correct set of rows that is to be returned to the UI-layer.
So our contract with the UI-developer will be:
- call a stored procedure supplying the three context variables, and then
- query the rows by doing a select * from a view (without any where-clause).

Let's develop the context procedure first. This requires:
- creating a (generic) package to populate name-value pairs inside a context
- creating a context specifically for this page and attaching it to the package
- creating a UI-interface object specifically for this page, using the package to enter the three name-value pairs into the context.
The package which has a "setter" to enter a name-value pair into a context (a.k.a. namespace):
create or replace package x_ctx asThe context that requires the package to populate it:
procedure p_set(p_namespace in varchar2
,p_attribute in varchar2
,p_value in varchar2);
end;
/
create or replace package body x_ctx as
procedure p_set(p_namespace in varchar2
,p_attribute in varchar2
,p_value in varchar2) as
begin
--
dbms_session.set_context(p_namespace,p_attribute,p_value);
--
end;
end;
/
create context bookorder_ctx using x_ctxAnd finally the UI-interface procedure:
/
create or replace procedure p_bookorder_ctxNow all that's left is to develop a view that uses a pipelined table function to retrieve the rows. A pipelined table function requires the creation of two types: a type that describes the structure of the rows that are being returned by that function, and on top of that, a table type. Here they are:
(p_username in varchar2
,p_ean in varchar2
,p_book_string in varchar2) as
begin
--
-- Put info in v$context.
--
x_ctx.p_set('BOOKORDER_CTX','USERNAME',p_username);
x_ctx.p_set('BOOKORDER_CTX','EAN',p_ean);
x_ctx.p_set('BOOKORDER_CTX','BOOK_STRING',p_book_string);
--
end;
/
create type f_bookorder_t is objectThese types are then used in the code of the pipelined table function:
(username varchar2(10)
,ean varchar2(9)
,title varchar2(95)
,amount number
,new_amount number)
/
create type f_bookorder_table_t as table of f_bookorder_t;
/
create or replace function tf_bookorderNote that I'm again hardcoding binds into the sql-text of the ref-cursor, which is of course a bad idea. The purpose here is to show the pipelined table function concept. Tim Hall has a great article here that demonstrates how the values available inside the context can be readily reused as binds, and (this is what makes it great as far as I'm concerned) at the same time preventing having to code different 'open ref-cursor for ... using ...' statements.
(p_username in varchar2
,p_ean in varchar2
,p_book_string in varchar2) return f_bookorder_table_t pipelined as
--
type refcursor is ref cursor;
c1 refcursor;
r1 f_bookorder_t;
pl_where varchar2(2000);
begin
--
if p_username is null
then
return;
elsif
p_ean is not null
then
pl_where := 'and o.username = '''||p_username||''''||'
and b.ean = '''||p_ean||'''';
elsif
p_book_string is not null
then
pl_where := 'and o.username = '''||p_username||''''||'
and upper(o.ean||'' ''||b.author||'' ''||b.title||'' / ''||b.publisher) like ''%''||'''||upper(p_book_string)||'''||''%''';
else
pl_where := 'and o.username = '''||p_username||'''';
end if;
--
open c1 for
'select f_bookorder_t
('''||p_username||'''
,b.ean
,o.ean||'' ''||b.author||'' ''||b.title||'' / ''||b.publisher
,o.amount
,to_number(null)) as bookorder
from book b
,bookorder o
where b.ean = o.ean '
||pl_where;
--
fetch c1 into r1;
--
while c1%FOUND
loop
--
pipe row(r1);
--
fetch c1 into r1;
--
end loop;
--
close c1;
--
return;
--
exception when no_data_needed
then close c1;
return;
end;
/
And finally here's the view on top of this table function:
create or replace force view v_bookorder asWe invoke the table function in the FROM clause while at the same time supplying it with the three values that have been set into the context.
select o.username
,o.ean
,o.title
,o.amount
,o.new_amount
from table(tf_bookorder(sys_context('BOOKORDER_CTX','USERNAME')
,sys_context('BOOKORDER_CTX','EAN')
,sys_context('BOOKORDER_CTX','BOOK_STRING'))) o
/
Using XML in the contract
As annouced in the previous post, we'll also quickly show a contract based on XML.
 So let's suppose the technology used for coding the UI-layer likes it when it gets an XML document that holds the rows that are to be displayed. Here's the procedure for a contract that returns the XML as a Clob:
So let's suppose the technology used for coding the UI-layer likes it when it gets an XML document that holds the rows that are to be displayed. Here's the procedure for a contract that returns the XML as a Clob:create or replace procedure get_xmlWe could of course also return a true XMLType value, by simply casting the Clob to XMLtype prior to returning it. Alternatively we could have built an XMLType value straight from the start by using all the XML function support available to us inside the DBMS.
(p_username in varchar2
,p_ean in varchar2
,p_book_string in varchar2
,p_xml out CLOB) as
--
type order_t is record
(username varchar2(10)
,ean varchar2(9)
,title varchar2(95)
,amount number
,new_amount number);
r1 order_t;
type refcursor is ref cursor;
c1 refcursor;
pl_where varchar2(2000);
begin
--
if p_username is null
then
return;
elsif
p_ean is not null
then
pl_where := 'and o.username = '''||p_username||''''||'
and o.ean = '''||p_ean||'''';
elsif
p_book_string is not null
then
pl_where := 'and o.username = '''||p_username||''''||'
and upper(o.ean||'' ''||b.author||'' ''||b.title||'' / ''||b.publisher) like ''%''||'''||upper(p_book_string)||'''||''%''';
else
pl_where := 'and o.username = '''||p_username||'''';
end if;
--
open c1 for
'select o.username
,o.ean
,substr(o.ean||'' ''||b.author||'' ''||b.title||'' / ''||b.publisher,1,95) as title
,o.amount
,to_number(null) as new_amount
from book b
,bookorder o
where b.ean = o.ean '
||pl_where;
--
fetch c1 into r1;
--
p_xml := ''||chr(10); ');
--
while c1%FOUND
loop
--
dbms_lob.append(p_xml,''||chr(10);
'||chr(10));
dbms_lob.append(p_xml,''||r1.username||' '||chr(10));
dbms_lob.append(p_xml,''||r1.ean||' '||chr(10));
dbms_lob.append(p_xml,''||r1.title||' '||chr(10));
dbms_lob.append(p_xml,''||r1.amount||' '||chr(10));
dbms_lob.append(p_xml,''||r1.new_amount||' '||chr(10));
dbms_lob.append(p_xml,'
--
fetch c1 into r1;
--
end loop;
--
close c1;
--
dbms_lob.append(p_xml,'
--
end;
/